
Adopción de bases de datos NoSQL: Mongo y Cassandra las más usadas
 Abraham
AbrahamEste mes de septiembre por primera vez hay dos bases de datos NoSQL entre el top 10 de las bases de datos más populares de DB-engines.com: Mongo y Cassandra. Ambas bases de datos están creciendo su adopción según este ranking; en el gráfico bajo estas líneas puede observarse de arriba a abajo la evolución a lo largo del último año y medio de Oracle, Microsoft SQL server, MySQL (las tres bases de datos que con diferencia lideran este ranking), Mongo y Cassandra:
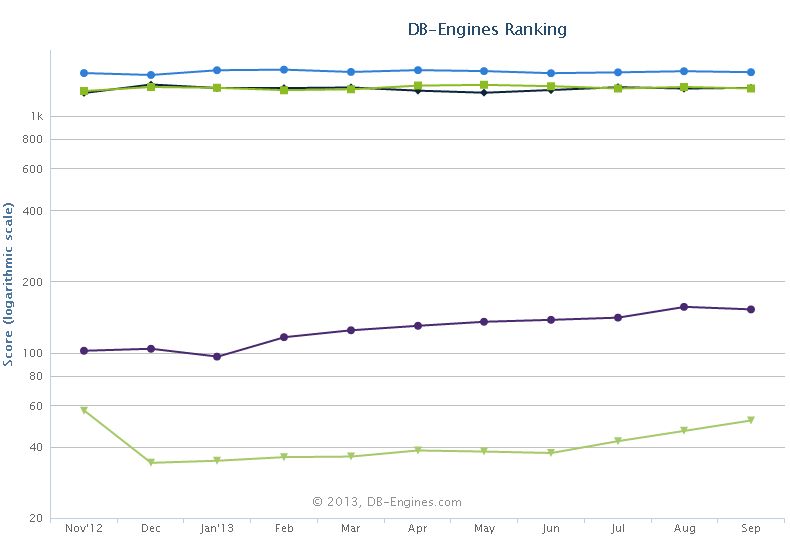
Y aquí tenéis el estado actual del top 10 de bases de datos más populares según este ranking:
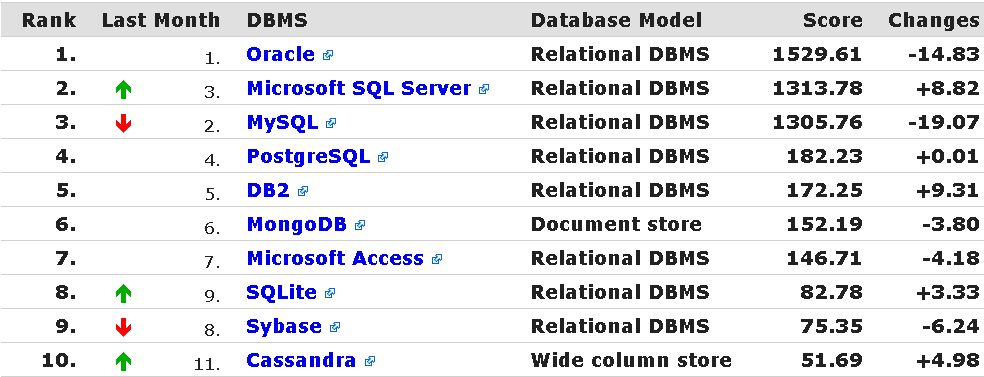
Estos datos se correlacionan bastante bien con una encuesta que se está realizando en Dzone donde se está tratando de medir el nivel de adopción de las distintas bases de datos junto con el valor que aportan, encuesta que se puede resumir en el siguiente gráfico bidimensional:
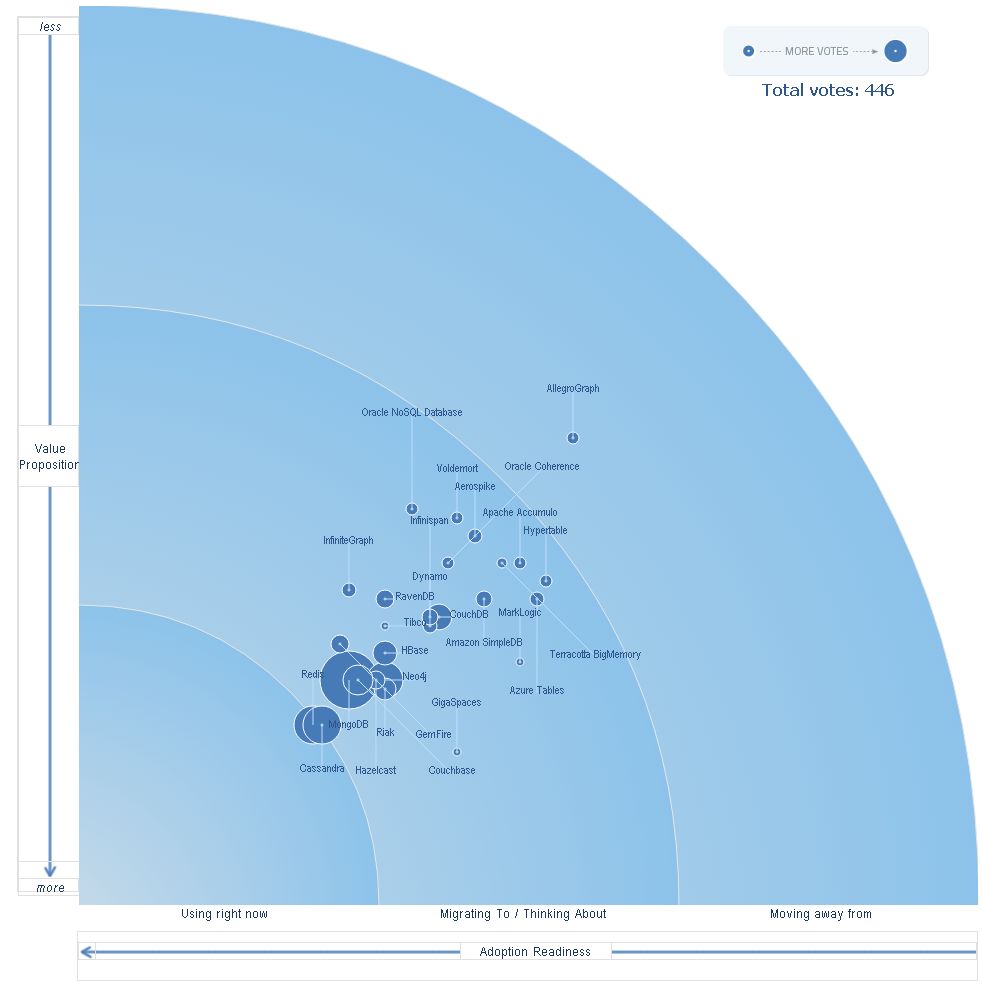
En este gráfico Mongo y Cassandra se encuentran también a la cabeza, aunque en este caso junto con Redis.
¿Cuantos por aquí empleais bases de datos NoSQL? ¿Cuál empleáis?
Reader Comments (7)
Actualmente estoy usando CouchDB y el problema que le encontré es que no soporta bien atributos grandes (maneja documentos en json). Tengo una aplicación en la que guardamos el log del resultado de un deploy con maven y tuvimos que cortar el log a unos 5000 caracteres.
Por encima de 10.000 la base ya se recentía.
Aclaro, que la base no está en una máquina potente, sino en una común con 4 GB ram.
Aún así si yo pusiera lo mismo en un MySQLl / PostgreSQL no creo que vaya a tener esos problemas.
Mas allá de esto, CouchDB está muuuy bueno. Tendría que probar MongoDB
¿Alguno sabe si alguno de estos motores NoSQL se aguanta tener un atributo grande?
Saludos
Yo use MongoDB en contra de la opinion de directores, jefes de proyecto y gerente. Que toda la vida se uso SQL para esas cosas, que era una frikada mia.......... Vamos que he recibido por todos los lados. Ahora me dicen que fue una decision estupenda que la aplicacion era imposible con una BBDD SQL.....................
Yo recomiendo MongoDB pero a la gente no tecnica le dices usar algo distinto a SQL y le entra sudores.
P.D.:En mongo no tienes problemas con ficheros grandes.
Si el problema del atributo grande es de rendimento, se puede decir que es normal. El JDK cuando pasa Strings a byte[] y viceversa no hace como C, donde un String es un byte[] acabado en cero y ya esta. Como usa Unicode y muchos juegos de caracteres se entretiene en hacer conversiones usando el juego de caracteres local, y eso no se nota cuando el String es pequeño, pero si es grande puede aburrir a una vaca.
Supongo que esa transformacion se hace al menos para mandar el String por la red en tu programa y despues no se que hara couchDB en recpecion porque de Erlang se como se escribe y poco mas.
Puedes probar a usar siempre byte[], tal y como lo lees del fichero, sin conversiones, si es que el API de couchDB te permite escribir byte[]. En cualquier caso, cuando se usan cosas grandes siempre se resiente el rendimiento.
@nilojg: lo que comenté del problema de rendimiento es con CouchDB no con java.
En todas las vistas en futon (el cliente web de la base) se nota un deterioro enorme en el rendimiento, al punto que puse una vista que me muestra cuando el atributo de un documento pasó cierto límite, por lo cual voy a mano y modifico lo que haga falta.....
Nosotros usamos mongoDB para algunas cosillas. Sustituimos un sistema de notificaciones para una red social con mysql por otro usando mongo, el anterior sistema tenia un cuello de botella enorme en las escrituras (hacían los insert de uno en uno usando hibernate... que el pobre mysql no tiene la culpa tampoco), la cosa es que con mongo podíamos hacer writes sin esperar confirmación (si se pierde alguno tampoco pasa nada, aunque después de varias decenas de millones no tenemos constancia de haber perdido ni uno solo...). el aumento de velocidad de 10 a 1 aprox y tenemos margen para optimizar muchas cosas más que no hemos optimizado porque no nos hace falta más velocidad de la que tenemos y seria perder el tiempo.
Poco a poco nos hemos ido animando a usar más mongo en nuevas features y cambiando el chip resulta que nuestros datos por normal general se ajustan mucho mejor a un sistema de almacenamiento de "documentos" que a un sistema relacional. Un ejemplo, pensar en las settings de un usuario en linkedin mismo, en un objeto puedes almacenar todas las settings del usuario usando json y en sql tendrías que tener un buen porron de tablas con sus relaciones.
No digo que siempre sea mejor, pero es muy buena cosa que ahora nos planteemos opciones como bases de datos documentales u otras como bases de datos de grafos en lugar de usar el mismo martillo para todos los clavos.
Así por curiosidad ¿a nadie la preocupa el ACID y la transaccionalidad o más aún la transaccionalidad distribuida?
¿Está el usuario preparado para hacer una operación y no ver el resultado de su operación en la siguiente pantalla? Esto es algo que se puede ver en un banco porque sabemos que las operaciones se tienen que aprobar que si tienen un intervalo de 24h blah blah. ¿Pero en cualquier otro contexto?
¿Estamos preparados para la redundancia (duplicación) de datos y la desnormalización para evitar joins?
¿Estamos preparados a que un crash haga perder operaciones de compra no consolidadas?
Yo es por hacer de abogado del diablo (en el infierno usan MySQL).
Entiendo que niveles como en Twitter, Facebook, Google etc se tengan que utilizar otro tipo de bases de datos para conseguir la escalabilidad brutal que necesitan (aunque creo recordar que Twitter sigue usando MySQL como su core aunque con otros muchos artefactos y anexos).
Mi impresión (refutable por supuesto) es que el 95% de los que se están aventurando en el mundo NoSQL no han ni siquiera probado a hacer un master/slave o un cluster de su BD relacional. Muchos me atrevería a decir que ni siquiera conocen que existen las transacciones distribuidas (JTA en Java) que permiten hacer transacciones compartidas en múltiples BD.
Entiendo que ese 5% restante "necesite más".
Hola, nosotros estamos probando OrientDB para json y grafos, usamos mongo para un par de cosas pero nuestro backend sigue siendo Postgresql.
Un saludo.