Curso de programación Java VI
Artículo publicado originalmente en la revista Sólo Programadores
Descargas
- Códigos del artículo
- Video del artículo (.exe para Windows)
- Video del artículo (.vvl para Linux)
- Video del artículo (.hqx para Mac Os)
- Video del artículo (.swf, flash multiplataforma)
En el número anterior cubrimos uno de los pilares básicos de la librería estándar de Java: el API de entrada y salida. En este número, abordaremos otro de estos pilares, aquel que está relacionado con el famoso libro "Algoritmos + Estructuras de datos = Programas" de Niklaus Wirth, el padre de Pascal. Más concretamente, abordaremos el framework de Collections de Java, framework que proporciona muchas de las estructuras de datos más comúnmente empleadas en computación, así como varios algoritmos (copiado, ordenación, búsqueda...) para trabajar con ellas.
Antes de comenzar a presentar este framework, necesitamos conocer un nuevo aspecto de la sintaxis del lenguaje Java que todavía no hemos abordado: su soporte para el polimorfismo paramétrico o plantillas. Esta característica se incorporó al lenguaje en Java 5, por lo que no está disponible en versiones anteriores.
1 Polimorfismo paramétrico en Java
El polimorfismo paramétrico, plantillas o (empleando un término inglés) "Generics" permite que un objeto pueda usarse uniformemente como parámetro en distintos contextos o situaciones. Las clases genéricas o paramétricas permiten definir clases que no se quiere o puede especificar completamente hasta determinar un tipo de dato. En estas clases el tipo concreto de datos que manipulan se especifica como un parámetro en el momento en que se crean los objetos de la clase.
Como todo tipo de polimorfismo, el polimorfismo paramétrico trata de abstraernos de algún detalle y permitirnos trabajar a un mayor nivel de abstracción. El "detalle" del que este polimorfismo trata de abstraernos es el tipo de dato concreto sobre el cual vamos a operar. Por ejemplo, supongamos que queremos construir una lista en Java; esto es, una estructura que puede crecer de modo dinámico y que contiene un conjunto de datos, cada uno de los cuales esta asociado con un dato anterior y un dato siguiente. Dado el primer dato de la lista, yo puedo recorrer todos los demás datos siguiendo las asociaciones de cada dato con su dato siguiente; también puedo realizar operaciones de borrado o inserción de datos en cualquier punto de la lista.
Para construir una estructura de este tipo, necesitaré algún tipo de contenedor que me permita almacenar tanto el dato que quiero contener, como algún tipo de referencia que me permita localizar cuál es el dato siguiente, y cuál es el dato anterior. ¿Cual sería la diferencia entre construir una lista de coches, una lista de lápices, float, int o una lista de java.lang.Object ? La única diferencia sería el tipo de dato que contiene la lista; la lógica de toda las operaciones de borrado, de inserción, de recorrido de la lista... sería idéntica. Si un lenguaje de programación me proporciona algún mecanismo para "abstraerme" del tipo de dato concreto que está manipulando mi lista, yo podía programar una lista que contenga cualquier dato.
Para esto es, precisamente, para lo que vale el polimorfismo paramétrico o generics: me permite especificar uno o varios datos que parametrizan una clase Java. La sintaxis para definir una clase Java genérica es la siguiente:
public class NombreClaseGenerica{
E dato;
E getDato () {return dato; }
}
Para crear una clase genérica, simplemente después del nombre de la clase tenemos que poner el parámetro (o lista de parámetros: NombreClaseGenerica) que parametrizan la clase. E puede ser cualquier clase Java. No puede, sin embargo, ser un tipo de dato primitivo (float, int ,...); en caso de necesitar que una clase sea para métrica respecto a un tipo de dato primitivo deberemos emplear no el tipo de dato primitivo, sino la clase wrapper correspondiente (Float, Integer ,...). Al construir un objeto de esta clase será necesario indicar cuál es el tipo de dato con el cual vamos a parametrizar esa instancia concreta de ese objeto; por ejemplo:
NombreClaseGenerica instancia1 = new NombreClaseGenerica ();
NombreClaseGenerica< MiClase > instancia3 = new NombreClaseGenerica< MiClase > ();
La primera sentencia construirá un objeto que pertenecerá a una clase que, a todos los efectos, estará definida como sigue:
public class NombreClaseGenerica{
Float dato;
Float getDato () {return dato; }
}
mientras que el objeto creado en la segunda sentencia pertenecerá a una clase de la forma:
public class NombreClaseGenerica{
MiClase dato;
MiClase getDato () {return dato; }
}
Una forma de ver el polimorfismo paramétrico es como un mecanismo para crear un conjunto ilimitado de clases donde la única diferencia entre ellas son los tipos de los datos sobre los que operan. Para aquellos que conozcan C++, mencionar que en Java el soporte para polimorfismo paramétrico es sólo a nivel de compilador: una vez el código ha sido compilado toda la información relativa a tipos genéricos se pierde, y sólo se obtiene una única clase compilada (a diferencia de C++, donde se obtiene una clase por cada tipo de parámetro diferente que hayamos empleado para parametrizar una plantilla). Con este esquema, el compilador puede realizar los chequeos de tipo de dato al trabajar con clases genéricas, y a la vez se mantiene compatibilidad con versiones de Java anteriores a Java 5, ya que en las clases compiladas no hay ningún tipo de información paramétrica.
En el listado 1 mostramos un código de ejemplo donde hay una clase que se parametriza con un tipo de dato. La clase tiene dos atributos del tipo que se emplea para parametrizarla, y permite modificarlos mediante dos métodos. La clase también tiene un método que concatena ambos datos en una cadena de caracteres. Desde otra clase, que contiene el método, main, se crean tres instancias diferentes de la primera empleando distintos tipos de dato como parámetro.
//LISTADO 1: Ejemplo de clase genérica
package capitulo6;
class Concatenador {
private E dato1;
private E dato2;
public String toString() {
return "El primer dato es: "+getDato1() +
" y el segundo es: " + getDato2();
}
public E getDato1() {
return dato1;
}
public void setDato1(E dato1) {
this.dato1 = dato1;
}
public E getDato2() {
return dato2;
}
public void setDato2(E dato2) {
this.dato2 = dato2;
}
}
public class Ejemplo1{
public static void main(String[] args) {
Concatenador concatenador1 = new Concatenador ();
concatenador1.setDato1(42.35F);
concatenador1.setDato2(2.365F);
Concatenador concatenador2 = new Concatenador ();
concatenador2.setDato1("Hola");
concatenador2.setDato2("Adiós");
Concatenador concatenador3 = new Concatenador ();
concatenador3.setDato1(23);
concatenador3.setDato2(246);
System.out.print(concatenador1 + "\n"+concatenador2
+ "\n" + concatenador3);
}
}
2 El framework de Collections
El framework de Collections fue incorporado a Java en la versión 1.2 por el arquitecto Joshua Bloch, uno de los principales gurús de Java. En Java 5 este framework sufrió una revisión bastante fuerte, el último trabajo que Bloch realizó en Sun Microsystems antes de irse a trabajar para Google, que consistió en soportar tipos de datos genéricos. Este framework se construye sobre las seis interfaces que, junto con sus relaciones jerárquicas, se muestran en la figura 1. En esta sección describiremos brevemente cada una de esas interfaces, así como sus principales implementaciones.
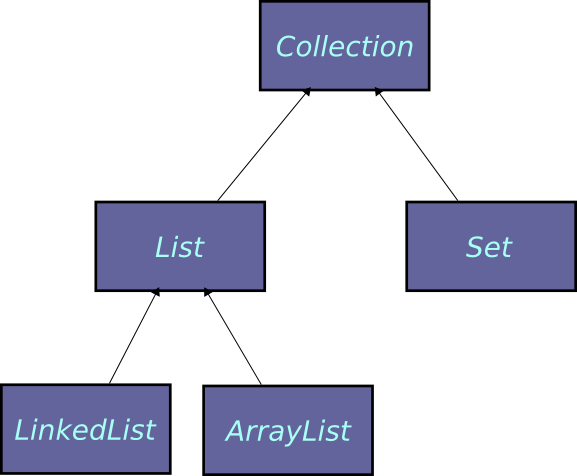
FIGURA 1: Las seis principales interfaces en las cuales se basa el framework de Collections
2.1 Collection
Se trata de una de las dos clases raíz de la jerarquía. Representa cualquier colección de objetos que pertenezcan a un mismo tipo, y proporciona operaciones para añadir y eliminar objetos de la colección, recorrer la colección, conocer el tamaño de la colección, etcétera. Más concretamente, los métodos que proporciona esta interfaz pueden clasificarse en tres categorías. Dentro de la primera, están los métodos para agregar y eliminar elementos de la lista:
- boolean add(E element): añade a la colección el elemento que se le pasa como argumento. Devuelve true si la operación se realiza con éxito, false en caso contrario.
- boolean addAll(Collection collection): añade a la colección todos los elementos de la colección que se le pasa como argumento. El tipo de dato con el que se ha parametrizado la colección argumento, y el tipo de dato con el que se ha parametrizado la colección sobre la que se invoca el método debe ser el mismo. Devuelve true si la operación se realiza con éxito, false en caso contrario.
- boolean remove(E element): elimina de la colección el elemento que se le pasa como argumento. Devuelve true si la operación se realiza con éxito, false en caso contrario.
- void clear(): elimina todos los elementos de la colección.
- void removeAll(Collection collection): elimina todos los elementos de la colección sobre la que se invocó el método que estén contenidos en la colección que se le pasa como argumento.
- void retainAll(Collection collection): elimina todos los elementos de la colección sobre la que se invocó el método que no estén contenidos en la colección que se le pasa como argumento.
El segundo tipo de métodos que contiene esta interfaz son métodos para realizar consultas:
- int size(): devuelve el número de elementos de la colección.
- boolean isEmpty(): devuelve true si la colección está vacía, false en caso contrario.
- boolean contains(E element): devuelve true si el elemento que se le pasa como argumento está contenido en la colección.
- boolean containsAll(Collection collection): devuelve true si todos los elementos de la colección que se pasa como argumento están contenidos en la colección sobre la que se invocó el método, y false en caso contrario.
Todavía hay una media docena más de métodos definidos en esta interfaz (el lector puede conocerlos consultando su javadoc), pero nosotros sólo vamos a ver otro más, uno de los métodos más importantes: Iterator iterator(). Este método nos devuelve un iterador. Un iterador es una interfaz que nos permite recorrer cualquier colección de elementos, y que tiene definidos tres métodos:
- boolean hasNext(): devuelve true si todavía quedan más elementos por visitar en la colección y false en caso contrario.
- E next(): devuelve el elemento al cual está apuntando el iterador y desplaza el iterador una posición hacia adelante dentro del contenedor.
- void remove(): elimina el elemento al cual está apuntando el iterador.
Una forma de recorrer una colección de elementos en Java es empleando un iterador:
Collection collection=...
Iterator it = collection.iterator();
while (it.hasNext()){//mientras queden elementos por recorrer
E elemento = it.next ();
...//realizar algún procesamiento sobre el elemento
}
2.2 La interfaz List y sus implementaciones más comunes
Esta interfaz representa una colección de datos ordenada en la cual se admiten datos duplicados y sobre la cual el usuario tiene control respecto a en qué posición de la lista se encuentra cada elemento. Podríamos pensar en este contenedor como en una lista doblemente enlazada, donde cada elemento tiene un elemento anterior y un elemento siguiente y donde, por tanto, la posición de cada elemento dentro de la lista está bien definida. Para dar soporte a las operaciones que permiten añadir un elemento en una posición determinada de la lista, borrar un elemento que se encuentre en una posición determinada, añadir una colección de elementos después de una posición determinada... esta interfaz añade los siguientes métodos respecto a interfaz Collection: void add(int index, E element), boolean addAll(int index, Collection collection), E get(int index), int indexOf(E element), int lastIndexOf(E element), E remove(int index) y E set(int index, E element). Los métodos int indexOf(E element) e int lastIndexOf(E element) devuelven la posición de la lista donde se encuentra la primera ocurrencia y la última ocurrencia, respectivamente, del objeto element. La funcionalidad de estos métodos debería ser obvia para el lector (en caso contrario, siempre puedes consultar su javadoc).
Otros métodos importantes de esta interfaz son ListIterator listIterator() y ListIterator listIterator(int comienzo). Ambos devuelven un objeto iterador adaptado a las características especiales de una lista; en el primer caso el iterador apunta al primer elemento de la lista, y en el segundo apunta al elemento que se corresponda con la posición que le pasamos como argumento. En el caso de las colecciones de elementos en general, no se puede asumir que dicha colección tenga un orden predefinido para acceder a sus elementos, por lo que el método iterator () de la clase Collection puede devolvernos los elementos de la colección en cualquier orden. Un ListIterator nos permite recorrer una lista en ambas direcciones (hacia adelante y hacia atrás) y partiendo de cualquier elemento de la lista. Para ello esta interfaz, además de con los métodos definidos en Iterator es, cuenta con los métodos boolean hasPrevious() y E previous(), que permiten recorrer una lista "hacia atrás". Por ejemplo, para recorrer una lista desde el último elemento al primer elemento podríamos emplear el siguiente código:
List lista = ...
ListIterator iterador = lista.listIterator(lista.size());
while (iterator.hasPrevious()) {//mientras haya anterior
E elemento = iterator.previous();
...//hacer algo con elemento
}
Las dos implementaciones más comunes de la interfaz List son ArrayList y LinkedList. Aunque ambas clases añaden algunos métodos respecto a los definidos en la interfaz List (y, por tanto, respecto a los definidos en la interfaz padre de List: Collection) estos métodos no son demasiado relevantes. El comportamiento básico de ambas clases está definido por los métodos de la interfaz List y Collection. La diferencia entre ambas es la implementación interna: ArrayList esta implementado internamente como un array, mientras que LinkedList esta implementado como una lista doblemente enlazada. Si bien esto no tiene ninguna implicación respecto a cómo se pueden usar las clases, sí tiene muchas implicaciones respecto a su rendimiento.
ArrayList es la clase ideal si vamos a realizar muchas operaciones de acceso aleatorio sobre la lista, ya que al estar implementado mediante un array dichas operaciones tienen un coste constante e independiente del tamaño de la lista. Sin embargo, esta clase no es la más adecuada si el tamaño de la lista va a estar creciendo y decreciendo continuamente, ya que implica reservar una memoria para el array interno; y las operaciones de borrado o inserción en el medio de la lista tienen un coste lineal con el tamaño de ésta, ya que potencialmente implican desplazar hacia adelante (en la inserción) o hacia atrás (en el borrado) todos los elementos de la lista. LinkedList por la contra tiene un rendimiento malo (lineal en el número de elementos) para las operaciones de acceso aleatorio, ya que pueden implicar recorrer todos los elementos de la lista. Sin embargo, las operaciones de borrado o inserción en el medio, o el crecer o decrecer dinámicamente su tamaño tienen un coste constante e independiente del número de elementos que contenga la lista (ver figura 2). Dependiendo de la aplicación concreta para la cual necesitemos la lista será mejor optar por una u otra implementación.
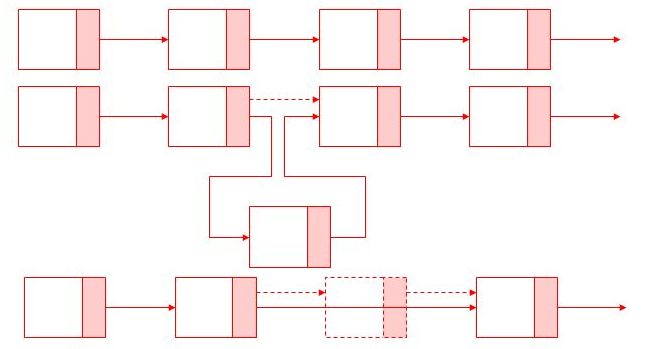
FIGURA 2: Operaciones de insertado y borrado en un LinkedList
En el listado 2 podemos ver un código en el cual se emplea una LinkedList para almacenar un conjunto de Strings (nombres de personas). Empleando el método que devuelve el iterador definido en la interfaz Collection recorremos la lista hacia adelante mostrando su contenido por consola. Después eliminamos un elemento y la recorremos hacia atrás empleando el iterador definido en la interfaz List. Observa como, a pesar de que se ha empleado un LinkedList, la variable en la cual almacenamos la lista es de tipo List; es decir, nuestro código no tiene ninguna dependencia con la clase concreta que esta implementando la lista más allá de la línea donde ésta fue creada. Por tanto, con sólo cambiar la línea de código:
List lista = new LinkedList();
por la línea:
List lista = new ArrayList();
habremos cambiado de una a otra implementación, sin necesidad de tener que modificar nada más en el código. Nuevamente, haré énfasis en que usar una u otra implementación tiene más impacto en el rendimiento del programa que en la forma de programar.
//LISTADO 2:
package capitulo6;
import java.util.*;
public class Ejemplo2 {
public static void main(String[] args) {
List lista = new LinkedList();
lista.add("María");
lista.add("Pedro");
lista.add("Jose");
lista.add("Marcos");
Iterator it = lista.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
lista.remove("Pedro");
System.out.println("Pedro borrado");
ListIterator it2= lista.listIterator(lista.size());
while (it2.hasPrevious()) {//esta vez vamos hacia atrás
System.out.println(it2.previous());
}
}
}
2.3 La interfaz Set y sus implementaciones más comunes
La interfaz Set no añade ningún método respecto a la interfaz Collection, pero se usa para representar conjuntos de elementos que no admiten duplicados. Por tanto, un Set necesita conocer si los objetos que contiene son o no iguales entre sí y esto, como veremos, no es completamente trivial.
Existen dos implementaciones principales de esta interfaz: HashSet y TreeSet. La primera almacena los datos utilizando una tabla hash. Podemos pensar en esta estructura como en un array que contiene en cada una de sus posiciones una lista de datos (ver figura 2). A partir de un dato, es posible de un modo simple y rápido calcular en cuál de las listas que contiene el array debe encontrarse dicho dato; esto es, a partir de un dato podemos calcular su hash, que de un modo directo nos indicará la posición del array. Mientras el tamaño de todas las listas sea reducido, el acceso a los datos es altamente eficiente.
Cualquier estructura de tipo Hash tiene dos parámetros que afectan a su rendimiento: el tamaño del array (que se conoce como capacidad) y su factor de carga. Este segundo parámetro es una medida de cuanto se permite que el array inicial se llene antes de incrementarlo de tamaño. Cuando el número de datos contenidos en la estructura excede el producto del factor de carga y de la capacidad, se duplica la capacidad de la estructura. Es posible especificar en el constructor de la clase HashSet ambos parámetros; habitualmente, un factor de carga de 0.75 (el que emplea el constructor por defecto de la clase) suele proporcionar un rendimiento bastante adecuado, aunque es posible jugar con estos parámetros para mejorar el rendimiento de una estructura tipo hash para una aplicación concreta.
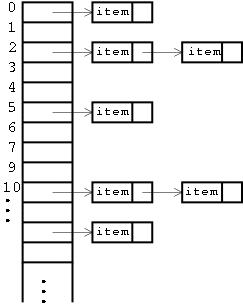
FIGURA 3: Esquema que representa la estructura interna de una tabla hash
Para que un HashSet funcione correctamente sobre instancias de clases que nosotros hemos creado (en el caso de clases de la librería estándar habitualmente quien las creó ya se ha encargado de resolver el problema que mencionaremos a continuación) debemos asegurarnos que los objetos instancias de dichas clases tienen bien definida la relación de igualdad. Esto es, que la clase define perfectamente cuando dos objetos son iguales. Para comparar objetos el framework de colecciones con frecuencia recurrirá al método equals de la clase Object:
boolean equals(Object obj)
Este método debe devolver true cuando el objeto que se le pasa como argumento es igual al objeto sobre el cual se invocó el método. En la implementación de la clase Object, este método sólo devuelve true cuando ambos objetos son idénticos, es decir, cuando son el mismo objeto. A menudo éste no es el comportamiento que queremos: no nos importa si son exactamente o no el mismo objeto, sino si su contenido es el mismo. Así por ejemplo los objetos f1 y f2 obtenidos de la forma siguiente:
Float f1 = new Float (4.345F);
Float f2 = new Float (4.345F);
no son idénticos, ya que f1 y f2 son dos objetos diferentes que están en posiciones diferentes de la memoria RAM. Por tanto, f1 == f2 es false. Sin embargo, son iguales ya que tienen el mismo contenido.
Para emplear cualquier clase que implemente la interfaz Set una de las cosas que debemos hacer es definir de un modo adecuado la relación de igualdad de las clases que queramos añadir al conjunto. Para ello debemos de sobrescribir el método equals de la clase Object de un modo adecuado. Como podemos ver en el listado 3, lo que este método debe hacer es comprobar en primer lugar si el objeto que se le ha pasado como argumento pertenece a la misma clase que el objeto sobre la cual se ha invocado el método, y a continuación realizar las comprobaciones pertinentes sobre los atributos del objeto. Estas comprobaciones dependen completamente de la naturaleza del objeto que estemos representando mediante la clase, y de cómo se defina la igualdad para dichos objetos.
Sin embargo, esto no va a ser suficiente para emplear la clase HashSet. Además de definir la relación de igualdad entre objetos, para poder emplear esta clase debemos asegurarnos que si dos objetos son iguales ambos tienen asociados un mismo hashcode. El hascode de un objeto se obtiene invocando el método int hashCode(), método que nuevamente está definido en la clase Object. Este es el método en el cual se va a basar la tabla hash para determinar la posición del array en la cual se debería encontrar la lista que contenga al objeto, en el caso de que el objeto esté contenido en la tabla. En la implementación por defecto de Object el hascode se basa en la identidad del objeto (habitualmente, en la posición de la memoria RAM en la cual se encuentra almacenado) y no en su igualdad; por tanto también debemos sobrescribir este método de tal modo que cuando dos objetos sean iguales según el método equals ambos tengan también el mismo hascode.
Lo dicho en el párrafo anterior es imprescindible para que las cosas funcionen: si dos objetos iguales no devuelven el mismo hascode esos objetos no serán manipulado de modo adecuado por el framework de colecciones. Sin embargo, idealmente, para que estos objetos sean manipulados además de correctamente de modo deficiente, los hascode de las distintas instancias de la clase deben estar distribuidos uniformemente sobre todo el rango posible de valores de hascode, y objetos muy diferentes deberían presentar hascodes muy diferentes.
En el listado 3 habríamos cumplido el contrato del método hashCode(), simplemente devolviendo el atributo valor de la clase MiEntero. Sin embargo, en este caso dos objetos diferentes que contengan números consecutivos tendrían hashcodes muy similares, lo cual no es bueno para el rendimiento de una tabla hash. La implementación del método hashCode() que se muestra en el listado 3 es la propuesta por Joshua Bloch en su libro Effective Java y se basa en la realización de varias operaciones de bits sobre un valor entero, y en añadir un valor de entropía aleatoria inicial. Poniéndolo en cristiano, y teniendo en cuenta que Bloch es quien ha diseñado el framework que estamos explicando en este artículo, es la implementación óptima para nuestro caso. Si nuestra clase tuviese más atributos sería recomendable tener en cuenta el valor de todos los atributos al generar el hascode. Bloch en su libro proporciona un complejo y efectivo algoritmo para la generación de códigos hash de calidad para casos más complejos que el nuestro.
//LISTADO 3: Ejemplo de uso de un HashTable
package capitulo6;
import java.util.*;
class MiEntero {
private int valor;
public MiEntero(int valor) {
this.valor = valor;
}
public boolean equals(Object o) {
if (!(o instanceof MiEntero)) {
return false;
}
if (((MiEntero) o).valor == this.valor) {
return true;
} else {
return false;
}
}
public int hashCode() {
return 37*17 + (int) (valor^(valor>>>32));
}
}
public class Ejemplo3 {
public static void main(String[] args) {
Set set = new HashSet();
set.add(new MiEntero(25));
set.add(new MiEntero(7));
set.add(new MiEntero(72));
System.out.println(set.contains(new MiEntero(5)));
System.out.println(set.contains(new MiEntero(25)));
}
}
La clase TreeSet representa un conjunto ordenado de objetos; este orden se basa en lo que en Java se llama "el orden natural" de los objetos, que viene definido por el método int compareTo(T o) de la interfaz Comparable. Otra forma alternativa de indicar cuál es el orden, si no podemos hacer que nuestros objetos implementen dicha interfaz, es proporcionarle al TreeSet en su constructor un objeto Comparator, objeto que define un método int compare(T o1,T o2) que permite comparar dos instancias de la clase T. El entero que devuelve el método compareTo debe ser negativo si el objeto que se le pasó como argumento va antes que el objeto sobre el cual se invocó el método; 0 si ambos objetos son iguales y positivo si el objeto que se le pasó como argumento va después que el objeto sobre cuál se invocó el método. El método compare debe comportarse de un modo análogo, indicando si el primero de esos argumentos va antes (devuelve un valor negativo), después (devuelve un valor positivo) o es igual (devuelve 0) que el segundo parámetro.
Tanto si implementamos la interfaz Comparable como si usamos un Comparator los resultados de ambas deben de ser compatibles con el método equals, ya que dicho método también será empleado internamente por la estructura. Esto quiere decir que si según el método equals dos objetos son iguales, al compararlos el entero que devuelva el método de la interfaz o del comparador debe ser "0".
El hecho de que un TreeSet sea un conjunto ordenado permite localizar los elementos dentro del conjunto de un modo altamente eficiente: la operación de localizar un elemento, añadirlo o eliminarlo tiene un coste log (n) respecto al tamaño del conjunto.
En el listado 4 podemos ver cómo hemos creado una clase Nombre que representa el hombre de una persona y su apellido. El orden natural de la clase indica que las instancias de la clase se ordenarán primero por nombre, y si el nombre es igual se ordenarán por apellido. También hemos creado una clase Comparador que implementa un orden diferente del orden natural: nos permitirá ordenar un conjunto de Nombres por apellido y, si el apellido es igual, se recurrirá al nombre. Esta es una de las utilidades de las clases Comparator: empleando distintos Comparators puedo ordenar una misma colección de objetos en base a diferentes criterios.
En el main del listado 4 creamos un primer TreeSet para el cual no indicamos ningún Comparator, por lo que empleará el orden natural. A continuación, empleando un iterador mostramos sus elementos. Después creamos otro TreeSet y esta vez especificamos que se emplee el Comparator que ordenará los objetos por apellido. En esta ocasión no empleamos un iterador para recorrer la colección, sino que empleamos el bucle "foreach" de Java. Este bucle permite recorrer cualquier colección de elementos; hasta ahora sólo lo habíamos empleado para recorrer los elementos de un array, pero podemos emplearlo sobre cualquier contenedor del framework de colecciones. A menudo esto resulta mucho más práctico para procesar una colección de elementos que emplear iteradores.
//LISTADO 4: Ejemplo de uso de TreeSet empleando tanto orden natural como un Comparator
package capitulo6;
import java.util.*;
class Nombre implements Comparable {
String nombre, apellido;
public Nombre(String nombre, String apellido) {
this.nombre = nombre;
this.apellido = apellido;
}
public int compareTo(Object o) {
if (nombre.equals(o)) {
return apellido.compareTo(((Nombre) o).apellido);
} else {
return nombre.compareTo(((Nombre) o).nombre);
}
}
public String toString() {
return nombre + " " + apellido;
}
}
class Comparador implements Comparator {
public int compare(Nombre o1, Nombre o2) {
if ( o1.apellido.equals(o2.apellido)) {
return o1.nombre.compareTo(o2.nombre);
} else {
return o1.apellido.compareTo(o2.apellido);
}
}
}
public class Ejemplo4 {
public static void main(String[] args) {
Set set = new TreeSet();
set.add(new Nombre("Juan", "Pérez"));
set.add(new Nombre("Antonio", "Rodríguez"));
set.add(new Nombre("Francisco", "Casado"));
Iterator it = set.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
Set set2 = new TreeSet(new Comparador());
set2.addAll(set);
System.out.println( "\nOrdenados por apellido:");
for (Nombre elemento : set2) {
System.out.println(elemento);
}
}
}
2.4 La interfaz Map y sus implementaciones más comunes
Se trata de la otra interfaz raíz de la jerarquía de colecciones de Java. Es una estructura dinámica de datos formada por una serie de parejas (clave, valor). Conociendo la clave es posible recuperar el valor correspondiente de un modo altamente eficiente. Una guía telefónica o un diccionario son ejemplos del mundo real que funcionan de un modo similar a estructura. En ellos la clave sería el nombre de la persona cuyo teléfono queremos averiguar o la palabra cuya definición estamos buscando, y el valor sería el número de teléfono y la definición, respectivamente.
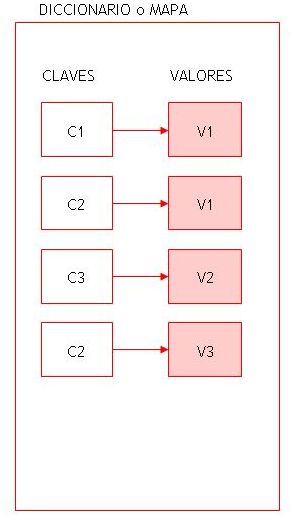
FIGURA 4: Estructura interna de un Map
Los principales métodos de este interfaz son:
- V put(K clave, V valor): permite añadir un par (clave, valor) al mapa. Devuelve el valor añadido si la operación se realizó correctamente o null en caso contrario.
- void putAll(Map mapa): añade el contenido del mapa argumento al mapa sobre cual se invoca el método.
- void clear(): elimina todo el contenido del mapa.
- V remove(K clave): elimina del mapa la clave que se le pasa como argumento. Devuelve el valor eliminado del mapa, o null sino se pudo realizar la operación.
- V get(K clave): recibe como argumento una clave, y devuelve el valor correspondiente o null si dicha clave no está en el mapa.
- boolean containsKey(K clave): devuelve true si el mapa contiene la clave.
- boolean containsValue(K value): devuelve true si el mapa contiene el valor.
- int size(): devuelve el tamaño del mapa.
- boolean isEmpty(): devuelve true si el mapa está vacío, false en caso contrario.
- Set keySet(): devuelve un Set con todas las claves del mapa.
- Collection values(): devuelve una Collection con todos los valores del mapa.
Existen dos implementaciones principales de este interfaz: HashMap y TreeMap. La primera implementa la interfaz basándose en una tabla hash, por lo que su contenido no estará ordenado. La segunda implementa la interfaz basándose en un árbol en el cual los datos están ordenados por valor ascendente de clave, empleando para este orden o bien el orden natural de las claves o bien un comparador que se le pasa en el constructor. Esta segunda implementación garantiza un coste log (n) para las operaciones de acceso o modificación a sus datos.
En el listado 5 podemos ver un ejemplo de uso de las clases HashMap y TreeMap. Primero creamos un HashMap empleando de clave un entero y de valor un String. Introducimos unas cuantas entradas, y las mostramos por pantalla empleando un iterador que itera sobre la colección de claves. Podemos ver cómo empleando esta implementación no tenemos ninguna garantía acerca del orden en el cual se van a almacenar los elementos. Después construimos un TreeMap con las mismas entradas. Como podemos ver en el código, en este caso las entradas estarán coordenadas por valor ascendente de la clave. Nuevamente, para que sirva de ejemplo, hemos empleado dos formas diferentes de recorrer cada una de las dos colecciones: en primer caso hemos usado un iterador, en el segundo un bucle tipo "foreach".
//LISTADO 5: Ejemplo de uso de las clases HashMap y TreeMap.
package capitulo6;
import java.util.*;
public class Ejemplo5 {
public static void main(String[] args) {
Map set = new HashMap();
set.put(11, "Once");
set.put(2, "Dos");
set.put(16, "Dieciséis");
Iterator it = set.keySet().iterator();
while (it.hasNext()) {
System.out.println(set.get(it.next()));
}
Map set2 = new TreeMap ();
set2.putAll(set);
System.out.println( "\nOrdenados:");
for (String elemento : set2.values()) {
System.out.println(elemento);
}
}
}
3 Algoritmos: la clase Collections
Si después de leer este capítulo decides consultar el javadoc de una sola de las clases aquí presentadas, ésta probablemente sería el mejor candidato. En esta clase hay una multitud de métodos estáticos que permiten realizar todo tipo de operaciones sobre colecciones de datos. Algunos de los métodos más relevantes son:
- static int binarySearch(List list, T key): busca en la lista que se le pasa como argumento el objeto que se le pasa como segundo argumento empleando el método de la búsqueda binaria. Devuelve el índice de la lista donde está el objeto, o un valor negativo si no lo ha encontrado.
- static void copy(List dest, List src): copia la segunda lista en la primera.
- static void fill(List list, T obj): llena la lista que se le pasa como argumento con copias del segundo argumento.
- static T max(Collection coll): devuelve el máximo de todos los elementos de la colección, según el orden natural. También es posible especificar un comparador.
- static T min(Collection coll): devuelve el mínimo de todos los elementos de la colección, según el orden natural. También es posible especificar un comparador.
- static boolean replaceAll(List list, T oldVal, T newVal): reemplaza todas las ocurrencias del segundo argumento en la lista que se le pasa como primer argumento por el tercer argumento.
- void sort(List list): ordena la lista que se le pasa como argumento empleando el orden natural. También es posible especificar un comparador.
En esta clase también existen otros métodos que proporcionan funcionalidad más avanzada, como crear copias no modificables (de sólo lectura) de una colección de elementos, o crear una colección de elementos sincronizada; esto es, una colección de elementos que podrá ser modificada desde distintos thread sin que ninguno de los thread puede encontrarse en algún momento que la lista está en un estado inconsistente.
En el listado 6 podemos ver cómo funcionan los métodos que nos permiten realizar búsquedas binarias y ordenaciones.
//LISTADO 6: Funcionamiento de la clase Collections
package capitulo6;
import java.util.*;
public class Ejemplo6 {
public static void main(String[] args) {
List lista = new LinkedList();
lista.add("María");
lista.add("Pedro");
lista.add("Jose");
lista.add("Marcos");
System.out.println("La posicin de Pedro es "+
Collections.binarySearch(lista, "Pedro"));
Collections.sort(lista);
System.out.println("Lista en orden alfabético:");
for(String elemento : lista){
System.out.println(elemento);
}
}
}
Dentro del paquete java.util también podemos encontrar una clase con una funcionalidad muy parecida a la de la clase de Collections, pero orientada a realizar operaciones sobre arrays: la clase Arrays. Esta clase nos permite ordenar arrays, buscar elementos sobre ellos, copiarlos, etc.
4 Conclusiones
El framework de Collections es una extensa y potente librería que recoge múltiples estructuras de datos en las cuales podemos apoyarnos para construir nuestros programas. Las estructuras de datos que hemos presentado en este artículo, aunque son las más empleadas, son sólo una pequeña fracción. Dentro de esta librería tenemos versiones de sólo lectura de todas las estructuras que hemos presentado en este documento, así como versiones sincronizadas (algunas de ellas, optimizadas para realizar múltiples lecturas y pocas escrituras; otras optimizadas para realizar múltiples escrituras). La librería también cuenta con pilas, colas, colas con prioridad, mapas de listas, listas secuenciales, colecciones cuyos elementos son referencias débiles que pueden ser reclamados por el Garbage Collector si la máquina virtual se está quedando sin memoria, y un largo etcétera.
Dentro de este framework también contamos con múltiples colecciones de algoritmos, contenidos en las clases Collections y Arrays, para realizar muchas de las operaciones más frecuentes que podamos realizar tanto sobre estas estructuras de datos, como sobre arrays. Según mi experiencia, dentro de este framework es posible encontrar cualquier estructura de datos que uno pueda necesitar, salvo un grafo. Para cualquier otra cosa, es extremadamente improbable que no encuentres una colección de datos adecuada dentro del framework.
Finalmente, aprovecho estas líneas para decirte que nunca deberías emplear en un programa las clases Vector o Hastable (sí, la "t" va con minúscula; esta clase es tan vieja que ni siquiera sigue los convenios de nomenclatura Java), clases que no pertenecen al framework de collections. Estas son clases legacy que se incorporaron a Java antes de que existiese el framework y que, por tanto, antes de Java 1.2 eran las únicas estructuras de datos que el lenguaje aportaba. Estas clases no estaban integradas dentro del framework de Collections, aunque en Java 1.2 se modificaron para que implementasen las interfaces List y Map, respectivamente. Sin embargo, estas clases están sincronizadas, esto quiere decir que siempre que se trabaja con ellas se obtiene una penalización en rendimiento en cualquier operación que se realiza sobre ellas, aunque nuestro código esté empleando un único thread. En la actualidad, no existe ningún motivo para emplearlas, a pesar de que por motivos históricos se usan mucho más de lo que se debiese: muchos programadores que aprendieron Java cuando estas clases eran las únicas alternativas nunca se han molestado en aprender nada nuevo.
En el próximo número continuaremos viendo más componentes de la librería estándar de Java: el framework de Swing, que nos permitirá construir aplicaciones gráficas de escritorio. Os espero a todos el mes que viene.
Cápitulos anteriores del curso:
- Curso de programación Java I
- Curso de programación Java II
- Curso de programación Java III
- Curso de programación Java IV
- Curso de programación Java V